agene

posted ![]()
![]()
posted ![]()
![]()
posted ![]()
![]()
posted ![]()
![]()
posted at 11:27 PM
0 comments
![]()
![]()
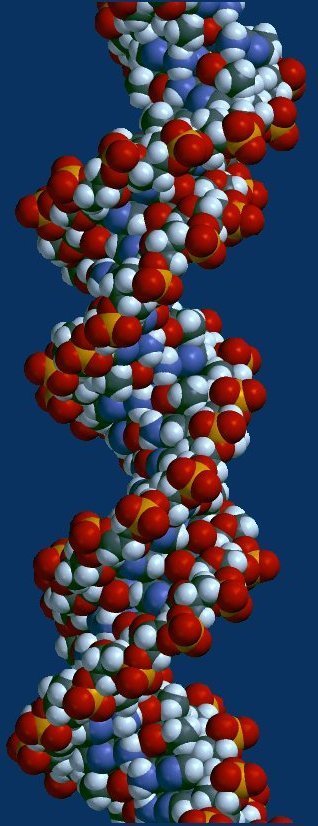
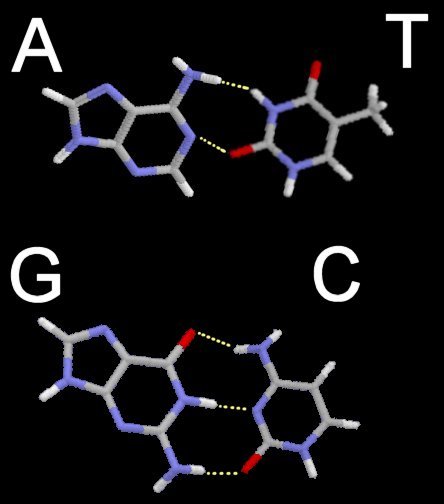
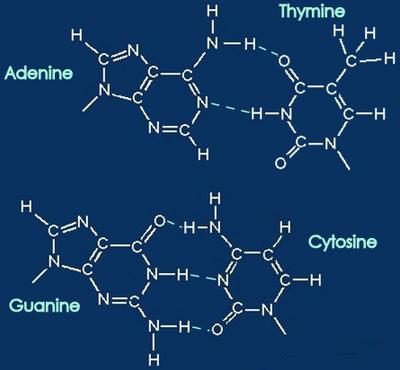 Above - nucleobases form complementary pairs through hydrogen bonding. Adenine and thymine are coupled (broken lines), and cytosine couples with guanine. Below left - stick model with hydrogen bonds as broken lines. (click to enlarge image)
Above - nucleobases form complementary pairs through hydrogen bonding. Adenine and thymine are coupled (broken lines), and cytosine couples with guanine. Below left - stick model with hydrogen bonds as broken lines. (click to enlarge image)
More at:
http://www.dnaftb.org/dnaftb/
http://www.dnalc.org/home.html
http://www.pbs.org/wgbh/aso/tryit/dna/
posted ![]()
![]()
posted at 11:24 PM
0 comments
![]()
![]()
posted at 11:24 PM
0 comments
![]()
![]()
posted at 11:24 PM
0 comments
![]()
![]()
posted at 11:23 PM
0 comments
![]()
![]()
posted at 11:13 PM
0 comments
![]()
![]()
posted ![]()
![]()
posted at 11:15 PM
0 comments
![]()
![]()
posted at 11:04 PM
0 comments
![]()
![]()
posted ![]()
![]()
In eukaryotes mechanisms for control of gene expression:
posted at 11:46 PM
0 comments
![]()
![]()
The genome possesses:
posted at 11:46 PM
0 comments
![]()
![]()
posted ![]()
![]()
posted at 11:46 PM
0 comments
![]()
![]()
posted at 11:22 PM
0 comments
![]()
![]()
posted ![]()
![]()
posted ![]()
![]()
posted at 11:19 PM
0 comments
![]()
![]()
posted at 11:10 PM
0 comments
![]()
![]()
posted at 11:09 PM
0 comments
![]()
![]()
posted at 11:08 PM
0 comments
![]()
![]()
posted at 11:07 PM
0 comments
![]()
![]()
posted at 11:06 PM
0 comments
![]()
![]()
posted ![]()
![]()
posted at 11:04 PM
0 comments
![]()
![]()
posted at 11:04 PM
0 comments
![]()
![]()
posted ![]()
![]()
posted at 11:20 PM
0 comments
![]()
![]()
posted at 11:16 PM
0 comments
![]()
![]()
posted at 11:15 PM
0 comments
![]()
![]()
posted at 11:14 PM
0 comments
![]()
![]()
posted ![]()
![]()
posted at 11:47 PM
0 comments
![]()
![]()
posted at 11:37 PM
0 comments
![]()
![]()
posted at 11:17 PM
0 comments
![]()
![]()
posted at 11:17 PM
0 comments
![]()
![]()
posted at 11:16 PM
0 comments
![]()
![]()
posted at 11:16 PM
0 comments
![]()
![]()
posted at 11:16 PM
0 comments
![]()
![]()
posted at 11:14 PM
0 comments
![]()
![]()
posted ![]()
![]()
posted at 11:18 PM
0 comments
![]()
![]()
posted at 11:12 PM
0 comments
![]()
![]()
posted ![]()
![]()
posted at 11:11 PM
0 comments
![]()
![]()
posted at 11:10 PM
0 comments
![]()
![]()







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}